
A Pan-Scots Rhyming Dictionary?
A Pan-Scots Rhyming Dictionary?
In which I act like a foolhardy 14 year old and plan to compile a Rhyming Dictionary with the help of twitter collaborators

Few months ago a chap called Albert Semple launched an online Scottish-English rhyming dictionary that he had constructed to remedy weaknesses in standard English rhyming dictionaries to match his own dialect and pronunciation. Another chap called Albert Kirk Jr saw this and mentioned that he’d thought about writing a similar thing for Scots. I dove in and suggested using the wordlist from my corpus, somehow.
The other day, the twitter thread came back and now my mind is racing… Can I do this? Can I write a Scots rhyming dictionary?
Rhyming strategies
Albert Semple’s strategy to construct a dictionary involved firmly establishing all the phonemes in his dialect, setting out the entire possible pronunciation space, then working back, eliminating invalid pronunciation combinations, and then populating the space with all possible word rhymes.
My strategy would be quite different. I’ve spent many years trying to come to terms with the phonetic alphabet and all the different symbols for vowels and consonants, and I can’t do it, my brain won’t let them in. Also I’m not Scottish, I don’t natively speak Scots, I have no indigenous Scots regional dialect.
Instead I have a corpus of Scots writing.
I can easily find out every rhyming word-pair that has been used in pieces of Scots poetry from the last 20 years. I just need to convert the list of word-pairs into something that might be useful.
Literature review
A quick literature review was fruitful. On Amazon, the “Look Inside” preview of the New Oxford Rhyming Dictionary, happens to include most of the introduction and notes about how the experts organise a rhyming dictionary.
First you look up the word you want to rhyme in the index:

Then you look up the relevant section number to find all the words that ought to rhyme with it:

At the start of the dictionary is a list of the sections or phonemes that all the rhymes are classified into:

The Penguin Rhyming dictionary follows a similar scheme



Penguin and Oxford University press probably have huge corpora and databases of rhymes and words in English, perhaps less so in Scots.
Is my corpus better than the big guys?
My dictionary
My dictionary would essentially have six sections:-
Phonetic Order / List of phonemes / Sections
Rhymes / Sections
Index
Reference list of all rhyme pairs in the corpus with citations
Bibliographic list of poems and sources
Practically I would generate a list of all the poetry lines in the corpus, then go through it line by line identifying all the rhyme pairs and then populating all sections of the Scots Rhyming Dictionary, one rhyme at a time.
Phonemes
We might note that the Penguin Phonetic Order list of phonemes includes about 48 different sounds, and the New Oxford Section list of phonemes contains about 35.
I’ve ripped off and bodged this list of phonemes that I understand just enough to get it to work
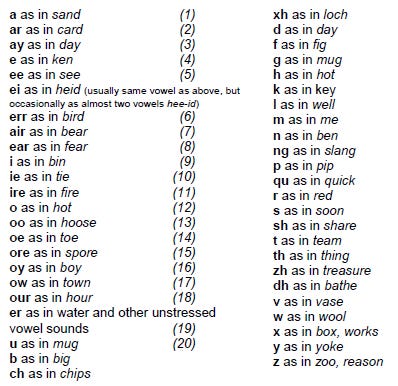
There’s some ambiguity. The word WA which means wall, could be pronounced as WAH, or as WAR, which is possibly the same as WAUR, or even pronounced as WAA where the ah is extended a little. Does it depend on how the reader is enunciating the word, or does it depend on the rhyme.
Does it even matter?
I got a bit over-excited and asked on the twitter whether HEID sounded the same as HEED, and DEID with DEED, the responses were ambiguous, but I came to the conclusion that it wasn’t worth agonising over. I’m no going to please everyone..
Dialects
But how to deal with regional dialects?
In JB Selkirk’s 1850 poem “A Border Burn”, he rhymes GHOST with LOST, this rhyme doesn’t work in modern standard English. I don’t know if this is a regional thing from the Southern Scots regional dialect, or just Selkirk pissing about. What I do know is that the rhyme happened once, just then, in the Southern Scots dialect.
As long as I tag that rhyme as being Southern (Sou) then users of the dictionary will be just as wary as I am.
So all the words are tagged up by dialect in the Rhymes section and the reference section.
Six regional dialects are used:-
Ulster-Scots
Central
Southern
Doric
Orkney
Shetland
If a schoolkid in Banff has to write a poem in Scots, they will be equipped to know which dialects the rhymes have been used in, and if any sound dodgy to their ear, they’ll have a clue about why.
Number crunching
The corpus contains about 393,000 words categorised as poetry, and perhaps 100,000 words categorised as children’s literature which might be poetry.
The poetry text is about 64,000 lines, with the children’s literature it could be a total do 80,000 lines of poetry. However, a quick sample suggests that only half of this is rhyming poetry (many Scots poets have transcended the need to rhyme), so 40,000 lines of rhymes or 40,000 rhyming words.
This would suggest 20,000 rhyming pairs, including many duplicates. I estimate one in ten rhymes are duplicates, the same rhyme used in multiple poems.
This suggests that an index would contain around 35,000 Scots words. In size 9 text, if they are listed 42 per column in four columns per page, this would take around 200 pages to list. If we reduce the text size to 6 which is the smallest legible to me, it could be around 40 pages.
From processing a sample of 500 words, 20 pages were required, the list of rhyme sections is 7 pages, the index is 3 pages and the rhyme pairs and citations is about 7 pages.
For a paper dictionary covering all 35,000 words, about 1,200 pages are required. Perhaps just covering a smaller fraction is more realistic.
From manually populating the sample, I can rack up about 100 words per day, so the full jobber would take about a year of populating. But a decent size of 2,000 words is just three weeks.
I’m being lazy / stupid. I could automate this. I have the skills to create a perl script that will take a csv spreadsheet of words and references and then layout a text file with all the phonemes and index etc.
Why am I just inserting and laying out one word at a time? When I could just populate a spreadsheet and let it go?
Proof of concept
Here is a link to the 20-page sample containing the first 500 words
It should be printable as a A5 booklet with a bit of faffing around with the pdf.